Adversarial examples
While we still really (really) far from creating skynet and the terminator we should keep in mind real problems that arises with the current state of the art in Artificial Intelligence. Besides being used for malicious purposes deep learning models can also be easily hacked.
Adversarial examples are one of the major threats to AI. Basically an adversarial example is a modified input example designed to force a wrong result in a machine learning model. An adversarial example can be created by adding perturbation signals in specific patterns. Perturbations can be subdivided in adversarial or universal.
Adversarial examples were introduced by Szegedy, et al., 2013 in
Intriguing properties of neural networks
[arxiv] when these researchers
were investigating neural networks properties.
Adversarial examples are input data modified with small perturbations especially
designed to trick an AI model to output incorrect answers with high confidence.
For example, Figure 1 demonstrates a perturbation signal that was added
to misclassify a panda as a gibbon.
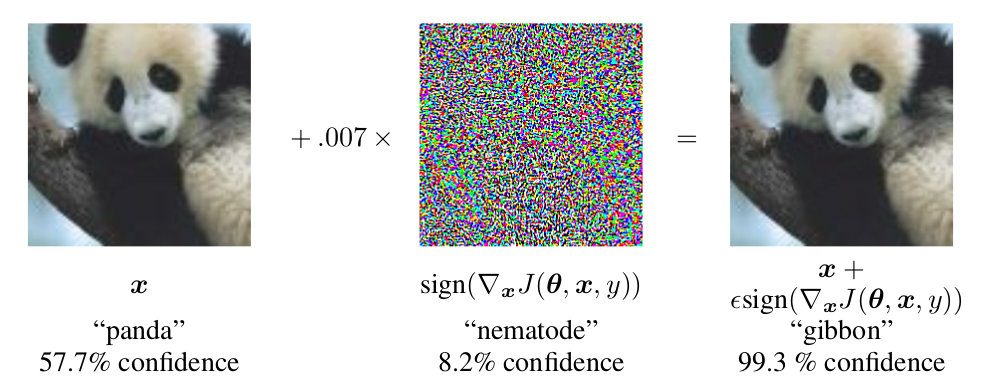
Explaining and harnessing adversarial examples, Goodfellow et al. 2015, [arxiv].
These modifications are in most cases imperceptible to the human eye. For instance, the panda image on right is indistinguishable to the image on left. This example demonstrates that machine learning models are able to learn and identify patterns we are not able to see. This situation poses an interesting question: does an AI model really needs to identify patters we don't perceive ?
Perturbation signals can easily fool state of the art models. The problem is very severe since anyone with a basic knowledge in deep learning is able to create adversarial examples. There are also several researches to create defenses on AI models but so far these defenses do not adapt to the type of the attack and can be easily defeated.
There are several reasons for the existence of this problem. Szegedy, et al. points out that these perturbations have a extremely low probability to exist on the dataset. It is impractical to create a dataset that contemplates every single possible entry a model can receive. With a better understanding of deep neural networks efficient countermeasures against perturbations could created.
A fun fact is that it is not only possible to fool machines but many projects
are being explored to fool humans, see
Adversarial Examples that Fool both Human and Computer Vision
,
Elsayed et al. 2018, [arxiv].
For instance, there are researches to reproduce someone else's voice and
researches to replace faces.
These researches among others in AI are very polemic.
These tasks are not new but the results obtained with the use of AI are
impressive.